Optimizing Spring framework database

Collection of useful or rather crucial information to know when dealing with database through Hibernate in Spring framework or ORMs in general, in order to avoid causing a bottleneck and a dramatic slowdown of the whole system.
Here we will focus on Spring framework and Hibernate ORM, where we will find usual slowdowns in database communications or operations and hidden traps but fear not, a lot of things here still apply to other ORM frameworks, even in other languages.
Why is my server performing so slow?
Developers are constantly racing as to what framework or router is the fastest and are constantly benchmarking hello world applications to show off how X is faster than Y, but in reality, in pretty much all projects I’ve experienced, what was really causing the slowdown was the database.
How do you notice what’s causing the slowdown?
The best way of discovery is if you use:
- Tracing like Jaeger and can see trace when queries are executed or database connections were acquired
- Logs before or after queries or if your framework provides database centric logs to measure time
- as last, real usage
Though the best alert is probably the manager yelling at you that the whole thing is slow as hell and that customers are complaining on slow performance.
Set up tracking of request response times and alerts on a threshold, test the performance of the APP when introducing new features or database related changes.
Most developers treat the database as a dumpster for data with unlimited performance, throwing anything inside without thinking about the schema (that’s why there is hype about MongoDB, it lets you do exactly that).
Problems with database arise when devs are:
- Not using indexes
- Making too many unnecessary queries
- Making bad/slow queries
- Fetching more than they need
- Not aware of ORM eagerly loading referential data
- Triggering accidentally ORM mapped entity referential data (see Entity relationship jackson)
- Not using read replicas properly
- Framework quirks that prematurely start transactions or end them too late (Quite a bit of this article)
- Bad database design
- etc etc

Because of these, database queries become dramatically slow, slowing down the server, which is especially noticeable in thread-per-request model like Spring framework and other languages that implement such a model, because each request will be prolonged and waste the thread by the amount of time it takes the database to respond.
Connection pools
Before we got to the framework and database library, we first we need to look into how an application establishes a connection to the database.
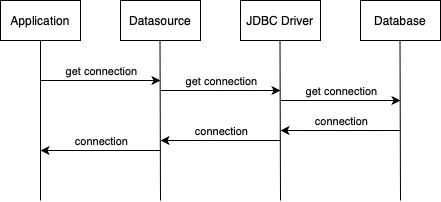
Datasource represents an ORM or similar implementation for data access. Here we see that each layer asks for a connection to the database before executing a query.
To acquire a connection to a database is costly, as it needs to go through a TLS handshake and on database side it creates a new OS process, consumes 5-10MB of RAM and creates more context switching for the CPU.
For comparison, a simple query would execute in 5ms, while acquiring a connection takes 100ms, so if we would acquire a connection every time, it would cost us 105ms.
Because of that, we use connection pooling on startup to create a connection pool, 10 connections by default if you are using Hibernate Hikari pool and store these connections for re-use when executing queries and re-open new connections when the pool is exhausted.
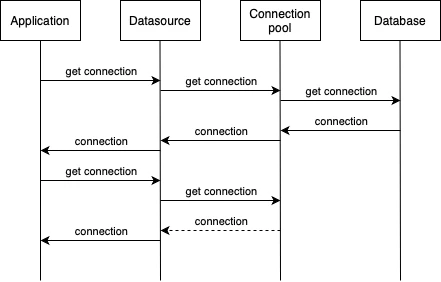
It would look, roughly, something like the above.
What should be the size of the pool? Size of the pool shouldn’t be too big, for example having 100 database connections would be an overkill, so only a dozen of pool connections should be maximum, like 10-30, but you should realistically stick with defaults and focus more on the queries and what you application is doing with them. Especially keep in mind that you might have multiple instances of your service and each one would start that big pools of connections, which can be too much on the database.
The black box

Spring hibernate ORM and JPA allow us to get started pretty quickly and provide many features for being productive fast
@Entity
class Person {
@Id @GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
// getters and setters omitted for brevity
}
interface PersonRepository extends Repository<Person, Long> {
Person save(Person person);
Optional<Person> findById(long id);
}
to accommodate this, there are a lot of things going on under the hood to make all that magic work, but to see behind the magic what’s happening, it’s of paramount importance when developing, to turn on database and SQL logs, that way you see what’s actually happening and what queries are being executed.
To show database and SQL logs set the following properties
# This will display SQL queries being executed
spring.jpa.properties.hibernate.show_sql=true
# Format the displayed queries
spring.jpa.properties.hibernate.format_sql=true
but if you need to also see the values being passed into the queries, not just prepared statements, you will need a proxy library to help you with that:
<dependency>
<groupId>com.github.gavlyukovskiy</groupId>
<artifactId>datasource-proxy-spring-boot-starter</artifactId>
<version>1.9.1</version>
<scope>test</scope>
</dependency>
then sprinkle a couple more of properties values and you’re good to go
# Show bind/passed values in the SQL statements
logging.level.org.hibernate.type.descriptor.sql=debug
logging.level.org.hibernate.type.descriptor.sql.BasicBinder=debug
logging.level.net.ttddyy.dsproxy.listener=debug
With this you would get the following logs (one of many) when running/testing your app
Hibernate:
SELECT
id
FROM
jobs
WHERE
(
name, unique_job_id
) IN (?)
2024-11-05T14:06:18.541+01:00 DEBUG 51306 --- [commandrunner] [omcat-handler-0] n.t.d.l.l.SLF4JQueryLoggingListener :
Name:dataSource, Connection:7, Time:3, Success:False
Type:Prepared, Batch:False, QuerySize:1, BatchSize:0
Query:["SELECT id FROM jobs WHERE (name, unique_job_id) IN (?)"]
Params:[([B@4927c530)]
Spring Transactions

Transactions not closing until request is done
Spring @Transaction annotation by default does not close the transaction until the whole request is done (probably
some unknown historical reasons).
Let’s look at the example bellow first.
@Service
class MyService {
@Transaction
public void hello() {
System.out.println(personRepository.findAll()); // Takes 20ms to fetch from database
}
}
and our controller service that calls MyService and executes an external request (which are typically slow)
@RestController
class MyController {
@GetMapping("/hello")
public void hello() {
myService.hello();
externalService.getData(); // Takes 500ms to get the data from the service
}
}
You would think that the transaction would start and end within the hello method, but actually it wouldn’t. The whole
database transaction would return in 520ms
And the 500ms come from here, we have another external call after the database action that prolongs the transaction.
This keeps the connection to the database unnecessarily too long (just count how many queries could there be done within those 500ms by other requests), thus it’s mandatory to have this disabled explicitly. We turn it off with the following property
spring.jpa.open-in-view=false
Transactions starting too early
Let’s do another example, but here we will first make the external call then execute the query.
@Transaction scope.@Service
class MyService {
@Transaction
public void hello() {
externalService.getData(); // Takes 500ms to get the data from the service
System.out.println(personRepository.findAll()); // Takes 20ms to fetch from database
}
}
In this example we get the same slowdown, though here the problem is that the
transaction has already been started at the beginning of the function, not at the first database request! So, the
transaction will again last 520ms instead of 20ms
To prevent Spring from starting transactions before the actual query is being made, we enable the following setting property.
spring.datasource.hikari.auto-commit=false
and now our transaction starts at: personRepository.findAll() invocation.
Transaction scope
When we wrap up a method with @Transaction annotation, we usually want to wait for all functionality after the database
call to finish without error so we can commit the database changes, and this is ok for a lot of use cases.
@Service
class MyService {
@Transaction
public void hello() {
System.out.println(personRepository.findAll()); // Takes 20ms to fetch from database
externalService.getData(); // Takes 500ms to get the data from the service
// Releases the connection
}
}
But let’s say we don’t care about the logic afterward and want to commit after the database operation completes,
one option is to move out the data out of the method (which is also a pretty good solution) into another that wraps
just that logic, the other is that we
use TransactionTemplate to programmatically set the selection for the transaction and commit.
It would look something like this
@Service
class MyService {
public void hello() {
transactionTemplate.executeWithoutResult(transactionStatus -> {
System.out.println(personRepository.findAll()); // Takes 20ms to fetch from database
}); // Releases the connection
externalService.getData(); // Takes 500ms to get the data from the service
}
}
This way you can customize, explicitly, within your business logic and don’t need the @Transaction annotation. But
again, depending on the custom scenario, because the annotation is much more manageable.
Entity relationships

Let’s have a user that has a one-to-many relationship mapping with addresses
@Entity
public class User {
@Id
private Long id;
private String role;
@ManyToOne()
private Account account;
@ManyToOne()
private User manager;
}
If we executed a query to retrieve users by the role of Admin
@Transaction
public void execute() {
List<User> users = userRepository.findAllByRole("Admin");
for(User user : users) {
System.out.println(user.getManager().getName());
}
}
users table, but we would execute huge amount of queries to fetch both the
accounts for each user and the manager for each user, when we just need the managers to get their name.To prevent that, we need to mark the User entity mapping to be lazily loaded, meaning only when we explicitly call
the method. We update the entity with following:
@Entity
public class User {
@Id
private Long id;
private String role;
@ManyToOne(fetch = FetchType.LAZY)
private Account account;
@ManyToOne(fetch = FetchType.LAZY)
private User manager;
}
Now we need to say explicitly in our query which type of associations we need
public interface UserRepository extends JpaRepository<User, Long> {
@Query("FROM users u JOIN FETCH u.account JOIN FETCH u.manager WHERE u.role = :role")
List<User> findAllByRole(String role);
}
JOIN FETCHreturns both tables (entities) that you indicated in the JPQL query.JOINreturns only one table (entity) from JPQL query.
These queries above can be lengthy and could lead to a mistake, so an alternative is that you can use @EntityGraph
public interface UserRepository extends JpaRepository<User, Long> {
@EntityGraph({"account", "manager"})
List<User> findAllByRole(String role);
}
fetch = FetchType.LAZY annotations to describe our fetching strategy, that makes it
static and there is no way to change the strategy, but this is exactly what the @EntityGraph allows us, to change it!Not everyone would be aware at first, but when you use entity as a DTO of a controller response, the Jackson mapping for example will trigger/invoke some methods and fields while marshaling to JSON and for example if you had a lazy laded relationship, Jackson will invoker that method that will then make an SQL query call to fetch the data, which can lead again to big and hidden performance hits to the database.
Setting the properties mentioned in the transaction section will omit errors for such cases, but still you should just spend a couple of minutes and re-map to the DTO what you want to return.
Batching
Another thing that isn’t switched on by default is the Spring insert batching. In same cases, you will end up producing
multiple INSERT statements instead of one when doing multiple inserts.
To enable batching to transform multiple INSERT statements into one, set the following property to your desired
batch size:
# sets batch size
spring.jpa.properties.hibernate.jdbc.batch_size=100
# groups entities
spring.jpa.properties.hibernate.order_inserts=true
Best practices
If possible, I would always opt for using just raw SQL queries. SQL is already a high level language with all the features you need to do almost anything. The programming language just sets arguments and parses the returned values into a class, that’s it!.

Though, let’s still go over best practices in Spring and when you don’t use raw SQL.
Native queries
Native queries might be a good approach most of the time as they let you write the exact SQL statement you want to execute, though let’s first check the default JPQL queries Spring has. Pagination JPQL query would look something like this:
interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT u FROM User u ORDER BY id")
Page<User> findAllUsersWithPagination(Pageable pageable);
}
We just declare the return type and argument type and that’s that, pretty neat.
Though, thankfully, we can still use the native SQL by setting the native flag to true.
interface UserRepository extends JpaRepository<User, Long> {
@Query(
value = "SELECT * FROM Users ORDER BY id",
countQuery = "SELECT count(id) FROM Users",
nativeQuery = true)
Page<User> findAllUsersWithPagination(Pageable pageable);
}
Pick the one that suits you the most, probably you will use JPQL for simple queries or simple abstractions, but will use native for complex and/or custom SQL queries.
Projections
Projections are important for query performance, because the less you select, the less lookup there is in the database for retrieval and fewer things there are to carry over the wire.
We can do a record projection selection, where Spring will magically figure out on return type what to return.
public record BaseFields(String id, String name, String role) {
}
public interface UserRepository extends JpaRepository<User, Long> {
BaseFields findBaseFieldsById(Long id);
}
If you are suspicious of this magic, you can instruct it with JPQL query
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT new BaseFields(u.id, u.name, u.role) FROM users u WHERE u.id = :id")
BaseFields findBaseFieldsById(Long id);
}
But, if you use native query you need to project to an interface
public interface BaseFields {
String getId();
String getName();
String getRole();
}
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT id, name, role FROM users WHERE id = :id", nativeQuery = true)
BaseFields findBaseFieldsById(Long id);
}
Which is ugly and weird 🤢.
Now imagine that you have same query, but multiple different projections, you would need to create that many queries for each projection. Thankfully, Spring has a feature that simplifies this, and it’s called dynamic projection.
public interface UserRepository extends JpaRepository<User, Long> {
<T> T findById(Long id, Class<T> clazz);
}
And with this, you end up with one query that’s flexible for projection selection of fields.
Efficient updates
Let’s take the following method for example, it would perform 2 queries, 1 to fetch the user and the other to update the user, also the update will update all the fields even though only 1 field was changed If you have any knowledge of SQL you know that this can fit into a simple and small single query update function.
@Transaction
public void execute(Long userId) {
User user = userRepository.findUserById(userId);
user.verify();
userRepository.save(user);
}
To make Hibernate use such statements we need to put the @DynamicUpdate annotation on the entity
@Entity
@DynamicUpdate
public class User {
@Id
private Long id;
}
Which will make the above code turn into an SQL: UPDATE users u SET u.is_verified = true WHERE u.id = :id
Query testing?
Sometimes you want to verify in your tests how many queries have been executed, to track and avoid possible anomalies. For that, you can rely on the QuickPerf library that provides utility functions for just that in your integration tests.
@UseCaseTest
class UserDatabaseTest {
@ExpectSelect(1)
@ExpectUpdate(1)
@ExpectDelete(0)
@Test
void execute() {
}
}
You can see above that we check that there were no DELETE statements, but exactly 1 SELECT and 1 UPDATE query executions.
References
These are some amazing videos where I got insightful info on the above-mentioned behavior which I suggest for everyone to watch.
Performance oriented Spring Data JPA & Hibernate by Maciej Walkowiak
Summary
Though this article serves as a reference when working with Spring data JPA and Hibernate, I want to put some key takeaways:
Just use SQL!
If possible, try just going down with the raw SQL, it’s already a higher level language abstracted to make writing queries easier, readable and efficient. The toolset is gigantic and ORMs will always miss features from it or be really late on implementing them.
But, in case you want to stick with ORMs like Hibernate, be wary of the following:
- Always log queries in development, to verify what’s being executed
- Use projection when you only need partial data
- Turn off the above-mentioned default features of Spring
- Be aware of database connection management
- ORMs complicate things, besides knowing SQL you will need to know the ORM and it’s inner workings
A lot of ORMs come to make database interaction easier and productive, but in the end complicate it and consume time. Once you spend a bit of time writing SQL queries, you find out that in the app you are just mapping data to send and data to receive.
Here’s a link for migrating away from an ORM that talks about many issues of an ORM.