Rise of concurrency

Concurrent programming has been out there for quite some time, take for example Erlang (1986.) and Lua (1993.) languages, but there is a period after 2012. or so, which, from my experience, seemed to receive the most evolutions in the land of web server concurrency development due to the increased requirement for efficiency and resilience.
A little bit of history
State of the web in the early days of Node.js…
In the past years of software development, lets around the year 2015., the demand for more engineers started to increase in linear fashion with no signs of stopping, as the number of projects increased or projects became bigger. Software landscape started to change, a lot of tools, solutions, languages and with them different styles of programming appeared, PHP 7 was a big thing, single page applications (SPA) were starting to become popular, and it was really an exciting time. Everything was moving at a fast pace and more people were pouring into this field.
Around the year 2016. I was working with PHP quite a bit, 2 years of college experience and almost a year professionally, arrived just when PHP 7 arrived, ecosystem was quite popular with a ton of frameworks being used, Docker appeared and was amazed that you could have multiple PHP versions on the same machine, Angular 1, etc. At that time I got introduced with Node.js (v0.11) through a presentation about its asynchronous I/O architecture and performance, that brought my attention as there is always a strive towards better performance in the web servers for handling high number of concurrent users at the same time.
A bit about PHP…
Because I worked with PHP the most, at the time, I want to show the comparison between the two I had at the time. PHP language was designed to be run as a single process via PHP interpreter through the likes of Apache server as a script, because PHP does not have its own web server (like Java has for example and note that the built-in one is for local dev only). So, the HTTP request handling works the following: the Apache web server (or Nginx + PHP-FPM if you’d like) receives 1 request for which it executes the PHP script that has a bit of HTML and a bit of PHP logic then again a bit of HTML then PHP, and so on, then spits out HTML. This also means there’s no persistent PHP process running, it just executes, does its job, returns the response and it’s ended. Because of this there were always troubles of doing long-running processes with PHP like Java does, it was just not made for that (you can kind of make it work, but it’s more of a hack for a language that was not designed for that from the start). Because each request gets its own short-lived PHP process you can as easily share state between (think of a simple example as a request counter), so you would need to use something like Redis, database, sessions, add-ons, C extensions, etc. PHP is literally a templating language with classes!
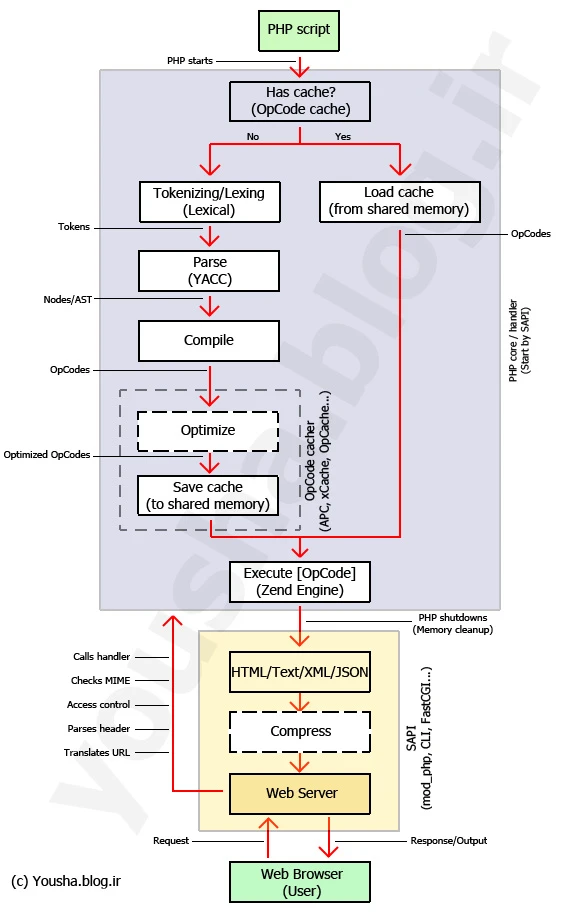
Because of this A lot of people that work with PHP whom I encountered and talked to are not even aware of that! That’s because a lot of them just start directly with a framework that hides all of this and get a false sense of what’s really happening underneath, when it’s just all files concatenated into a one file. Now we got syntactic sugar with PHP 8 (which is great), but people see that things look similar to other languages and say that it’s the same thing, still not knowing how the language works at its core.
Thread/process per request model
But to get back to the 1 process per request architecture. This means that for each request we would execute a PHP script in a worker process, and they can be quite heavy memory wise 1-2mb like a thread in Java. This means you can have only so many of them, for example for a small VM instance you will probably have a limit of 200 running concurrently at the same time. Every new request will need to wait for one of these running to finish before it could get started. If let’s say, 1 request takes 1 second to process and to return a response, that would mean our instance would serve 200 requests per second which is amazing as most software don’t get to have even 20 req/sec when they are a young product (or even a medium). A lot of other languages at the time work like this, for example: Ruby, Python and Java.
Thing about 1 request per process/thread is that they are wasteful when there is I/O file access or network communication by orders of magnitude because in those moments the process (which is sequential blocking) just blocks and waits for a response, doing nothing while holding precious memory!
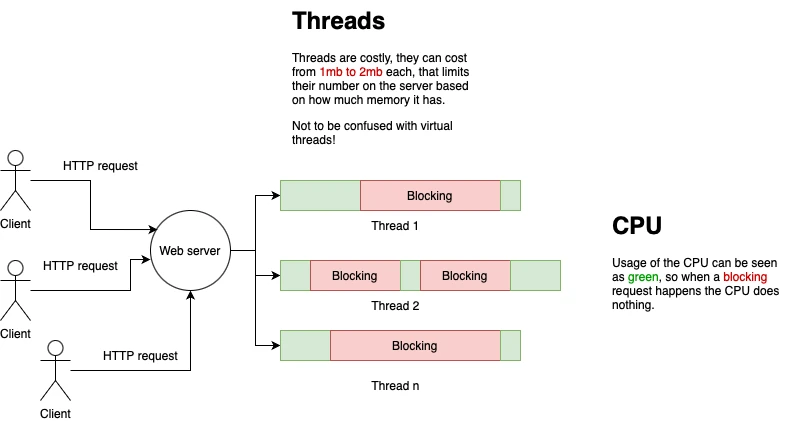
Now, where problems start to erupt…
So, to take that into perspective looking at our previous 200 req/second server. If we add in that PHP script a request to the database to retrieve some data with a heavier query that lasts 3 seconds (awaits response), so 4 seconds to process 1 request in total instead of 1, we would have throughput of reduced to 50 req/sec! All of them are holding to the memory for those 3 seconds, not doing anything but waiting! Worst thing is I usually tend to see services having multiple I/O requests that would take somewhere between 3 seconds to 15 seconds before timing out, can you calculate how many requests per second it would process then? Though you can always throw money to increase the memory and the number of instances to handle more, but here we are not talking about that, we are talking about efficiency.
In these scenarios you would focus on minimizing I/O, as the goal is for the thread to be done as soon as possible in order to serve the next request. If we had a thread before taking 1 second to process a request, reducing it’s time to 200ms would mean we can handle 5x more requests!
Some ways of reducing I/O would be:
- Circuit breakers, so that we fail fast if we notice other service failing often with 500+ status codes
- Optimizing queries, to retrieve what we need or improving the query or properly using indexes
- Offloading unnecessary work to async queues, let someone else do the work we don’t need to do immediately like email sending
- Caching, either data or the whole response
- More machines, standard answer of throwing money at the problem. Get more RAM
- …and other
Async I/O model
Node.js comes in to resolve those thread per-request issues by introducing an event loop implementation that will offload that thread blocking nature and only handle on callbacks or just when there is actual work that needs to be done.
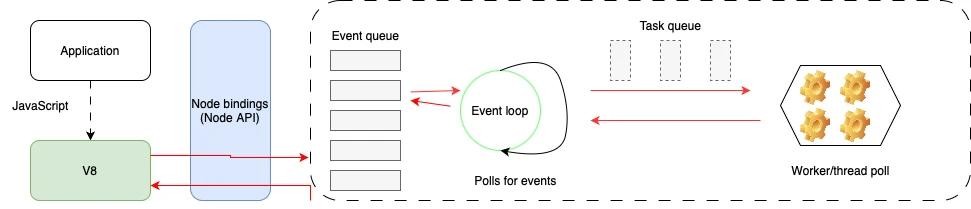
In the event loop, everything revolves around events, they get queued and once they are ready their handlers (tasks) get called on the CPU. If the handler has an IO call, it then gets moved away from the CPU and back to the event queue, so that the next task that needs actual processing starts on the CPU. Then, when the previous handler’s callback gets resolved, it gets put back on the event queue and so on.
Because of that, the CPU usage now looks like the following:
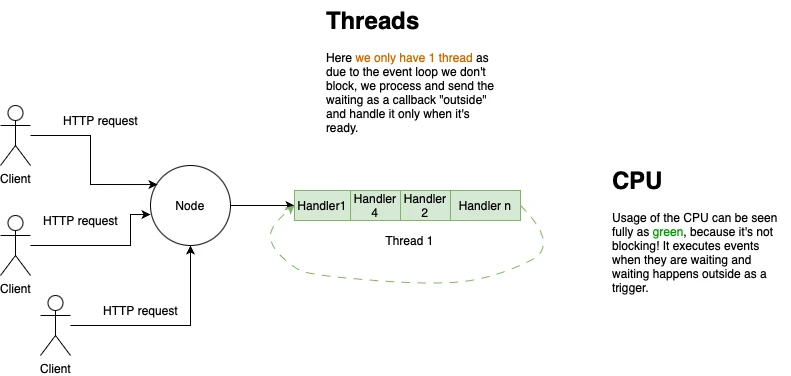
As it can be seen, there is no blocking of the thread, which allows 1 thread to handle up to thousands of requests per second by only itself and achieve efficient CPU and much less memory usage.
Example of how the second argument would be a callback function that would get called once the endpoint would get triggered.
app.get('/hello-world', (req, res) => {
res.send('Hello World!')
})
The maximum response time benchmark would look something like the following (lower is better):
⚠️ This is a rough estimate based on 1 second per request processing time without measuring actual work. It will always depend on the app what’s it doing, is there a lot of CPU work or just IO or a mix of the two, framework implementations and so on.
After 1 point the server will just stop serving requests and fail due to memory limit on the machine. It also depends on the way new TCP connections are established how well it will handle them.
‼️ Important
When it comes to a design that utilizes an event loop, it is of imperative notion that you never block the event loop thread! Performing high CPU consumption work on an event loop thread will block all other handlers to wait for that, for example calling a sync file read/write operation or if it’s a massive computation.
To put this into perspective, if you have a badly designed endpoint which reads from a file in a sync manner and it takes 1 second to handle a request, and you get 100 requests at the same moment: first user will get a response in 1 second, but the last user (you cannot be sure who it will be) will get the response in 100 seconds!
😎 A wave of popularity started…
With Node.js, the popularity of async programming started due to the simplicity of callback-like design, so it was easy for developers to achieve high concurrency with no difficulties. You only had 1 thread, so you wouldn’t run into standard concurrency problems and also that JavaScript was already widely used on front-end by everyone as there were quite a bit of full-stack engineers and soon a lot of libraries would start to pop like: express.js, koa.js and at the time of this writing currently popular Nest.js. One of the best uses was for sockets like socket.io which would need to have high number of open socket connections.
- Microsoft first released a version of C# with async/await in C# 5 (2012)
- Haskell got the async package in 2012
- Python added support for async/await with version 3.5 in 2015 adding 2 new keywords, async and await
- In Java (and other languages) there were already such solutions like Netty that provided non-blocking network applications, though I noticed that around the period of 2016. there was a bigger jump towards it and I have a feeling it was due to Node.js bringing so many people to it.
Reactive programming
This influenced others like in Java ecosystem to create a similar framework Vert.x to handle requests in a non-blocking way
import io.vertx.core.AbstractVerticle;
public class Server extends AbstractVerticle {
public void start() {
vertx.createHttpServer().requestHandler(req -> {
req.response()
.putHeader("content-type", "text/plain")
.end("Hello from Vert.x!");
}).listen(8080);
}
}
This further pushed the reactive style of programming, with a completely different way of handling data and events. But as that’s a big story of its own, we’ll leave it for another article.
Another a bit popular was the Java Spring framework with Spring Webflux
⚠️
But there is a big downside do reactive programming, and it’s that it becomes increasingly difficult to understand when things become a little bit more complex and even worse, debugging when an error is thrown. Even people who spend years working with reactive style of programming will find it hard to work and especially maintain. Procedural programming is still the best way to program and understand what’s happening and that’s why it didn’t spread as much.
Virtual threads
Problems with async/await is that it introduces a 🔴/🔵 “colored function problem”, meaning that if a function that’s not IO (🔵) calls a function that is IO bound (🔴) it will require you to update the first function to also become IO (🔴). This spreads like cancer quickly through the codebase, let alone talk about libraries and having to re-adjust everything. Libraries make up the ecosystem, you don’t want to go all out and start breaking the entire ecosystem through and through.
Virtual threads 🔀 come as an alternative to this and require zero changes to the code as the handling of IO and non-blocking is handled “under the hood”. Unlike traditional threads with weigh 1-2Mb, virtual threads have a stack of a few kilobytes, significantly smaller. This allows to run, theoretically, a million of them on a small app. This approach leaves the developer to not have to worry about offloading blocking work and what to mark as an async function and to easily integrate existing and new libraries.
Virtual threads can be seen as another layer of threads atop of threads, where you would have an internal scheduler which would track when a virtual thread would start blocking and move it out of the real thread, until it unblocks, then it would move it back to the thread.
The Go language with its goroutines was built from the ground up with concurrency in mind and is considered the language with best and easiest concurrency.
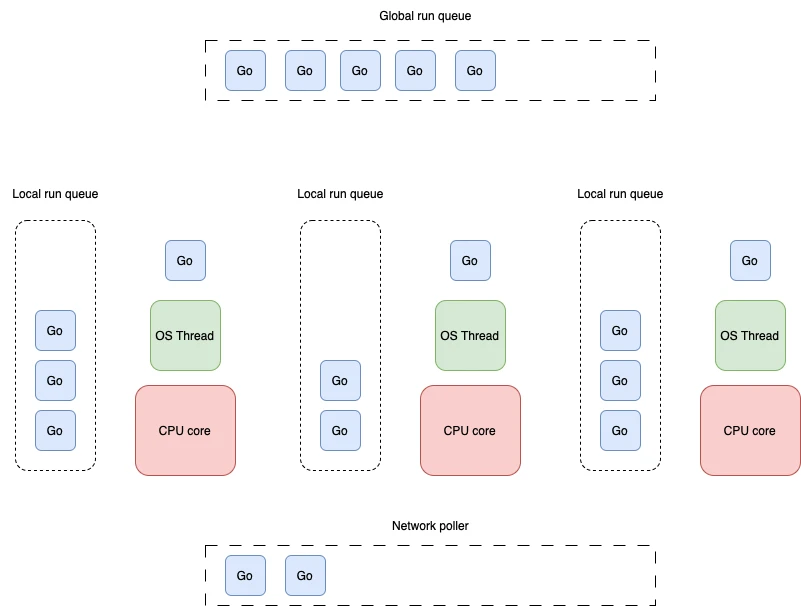
In Go, you would offload a task onto it’s goroutine just by using the keyword go
func main() {
// Send off work to a goroutine and handle results
go func () {
result, err := doWork()
// handle results...
}
}
And an amazing introduction to channels for handling more complex concurrency composition (now coined structured concurrency by Java)
package main
import "fmt"
func main() {
messages := make(chan string)
// In another goroutine send the message to the channel
go func() { messages <- "ping" }()
// Block and wait for a message from the channel
msg := <-messages
fmt.Println(msg)
}
We have blocking logic, but without actually blocking the thread and wasting CPU.
Java recently introduced virtual threads in JDK version 21 as part of the “Loom project” where they decided it was much better to go in the direction of virtual threads than async/await due to the “colored function” problems, especially since Java is carrying a huge ecosystem on it’s back that it wants to support in a backwards manner.
They were made to be a drop-in replacement with standard thread scheduler usages, so that library maintainers need only a couple of lines of changes (hopefully).
public static void main() {
try (ExecutorService myExecutor = Executors.newVirtualThreadPerTaskExecutor()) {
Future<?> future = myExecutor.submit(() -> System.out.println("Running thread"));
future.get();
System.out.println("Task completed");
// ...
}
}
Because of that, some frameworks like Spring boot just need a 1 line change to turn on usage of virtual threads for request handling.
spring.threads.virtual.enabled=true
Next steps in Java, is the structured concurrency design for easily handling and organizing multiple virtual threads.
Summary
It’s interesting to see how each language is trying to evolve and accommodate for increases in HTTP traffic and try to be as efficient as possible and having everyone learning from others on the pros and cons of each. Not to forget, the most important part at the end is to make things easy, not complex to work with. Go with virtual threads and channels seems to have won in concurrency design and even though I sometimes like reactive programming I think it’s the worst to maintain, especially within a team of developers, though some frameworks built on top of a reactive paradigm like Quarkus make it much easier and also optional.
Nevertheless, it’s important to know what you are building in order to properly utilize it, for example if you don’t have any IO it will be better just to use a thread directly and if latency matters you might want to avoid an event loop and let the scheduler better schedule virtual threads than having a starvation like long response.
Knowing how your programming language concurrency works is of paramount importance, so you hopefully don’t make big mistakes.
💡
From my experience I’ve seen developers struggle more with producing quality software, causing requests handlers to be extremely slow ranging from 5 seconds up to 15-20 seconds (imagine in microservice ridden system) and slowing throughput of the thread-per request application by that many times.
This was mostly due to issues with bad database design and having long complex queries or fetching unnecessary data, no indexing, doing things that should be done async or just hammering the database with queries much more than necessary.
When done correctly, and I mean just basic 101 programming like avoiding re-fetching, multi-updates and precise selects (not talking circuit breakers, caching and so), with a 200ms response, a single small instance would serve easily roughly 500 requests per second. Spoiler, most production services don’t have that many users to begin with. But maybe that’s why high concurrency is popular, so that bad code could continue to run instead of crash 🤔